Python3入门机器学习 - 集成学习
本文共 3477 字,大约阅读时间需要 11 分钟。
集成学习是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法。
#准备数据X,y = datasets.make_moons(noise=0.3,n_samples=500,random_state=42)from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)#逻辑回归预测from sklearn.linear_model import LogisticRegressionlog_reg = LogisticRegression()log_reg.fit(X_train,y_train)log_reg.score(X_test,y_test)#SVM预测from sklearn.svm import SVCsvc = SVC()svc.fit(X_train,y_train)svc.score(X_test,y_test)#决策树预测from sklearn.tree import DecisionTreeClassifierdec_clf = DecisionTreeClassifier()dec_clf.fit(X_train,y_train)dec_clf.score(X_test,y_test)y1_predict = log_reg.predict(X_test)y2_predict = svc.predict(X_test)y3_predict = dec_clf.predict(X_test)#使用集成学习的方法决定最终预测结果y_predict = np.array((y1_predict+y2_predict+y3_predict)>=2,dtype='int')
使用sklearn中的VotingClassifier
from sklearn.ensemble import VotingClassifiervoting_clf = VotingClassifier(estimators=[ ('log_clf',LogisticRegression()), ('SVM',SVC()), ('dec_clf',DecisionTreeClassifier())],voting='hard') #hard为少数服从多数的集成学习方式voting_clf.fit(X_train,y_train)voting_clf.score(X_test,y_test) Soft Voting

Soft Voting这种方式必须要模型具有预测概率的能力,例如逻辑回归算法本身就是基于概率做分类的,而knn算法一类的非参数学习方法,也可以根据样本数据预测概率,SVM算法可以将probablity属性设置为True以支持概率预测。
voting_clf2 = VotingClassifier(estimators=[ ('log_clf',LogisticRegression()), ('SVM',SVC(probability=True)), ('dec_clf',DecisionTreeClassifier(random_state=666))],voting='soft')voting_clf2.fit(X_train,y_train)voting_clf2.score(X_test,y_test) 使用Bagging产生大量子模型的集成学习方法
让每个子模型只看数据的一部分,用放回取样的方式来训练大量的子模型,作为集成学习的方法。
from sklearn.ensemble import BaggingClassifier#创建Bagging集成学习的参数#使用DecisionTreeClassifier()作为子模型,决策树作为子模型更容易创建子模型间的差异性,对于Bagging这种方式的集成学习来说,决策树是相对较好的子模型选择#max_samples决定每个子模型最多参考样本数据量#n_estimators决定生成多少个子模型#bootstrap决定采用放回抽样还是不放回抽样,True为放回抽样bagging_clf = BaggingClassifier(DecisionTreeClassifier(),max_samples=100,n_estimators=500,bootstrap=True)
上例为对样本进行随机采样,但对于Bagging,其实有更多的方法可以进行采样来创建子模型

Random Subspaces
#max_features设置随机取的最大样本特征数量#bootstrap_features设置对特征进行放回或不放回取样#oob_score设置对所有样本进行采样,不分离训练和测试数据集,而在随机采样中所有没有被采样的数据作为测试集使用random_subspaces_clf = BaggingClassifier(DecisionTreeClassifier(),max_samples=500,n_estimators=500,bootstrap=True, max_features=1,bootstrap_features=True,n_jobs=-1,oob_score=True)random_subspaces_clf.fit(X,y)random_subspaces_clf.oob_score_
Random Patches
random_patches_clf = BaggingClassifier(DecisionTreeClassifier(),max_samples=100,n_estimators=500,bootstrap=True, max_features=1,bootstrap_features=True,n_jobs=-1)random_patches_clf.fit(X,y)random_patches_clf.oob_score
随机森林
from sklearn.ensemble import RandomForestClassifierrf_clf = RandomForestClassifier(n_estimators=500,oob_score=True)rf_clf.fit(X,y)rf_clf.oob_score_
Extra Trees
from sklearn.ensemble import ExtraTreesClassifieret_clf = ExtraTreesClassifier(n_estimators=500,oob_score=True,n_jobs=-1,bootstrap=True)et_clf.fit(X,y)
Boosting
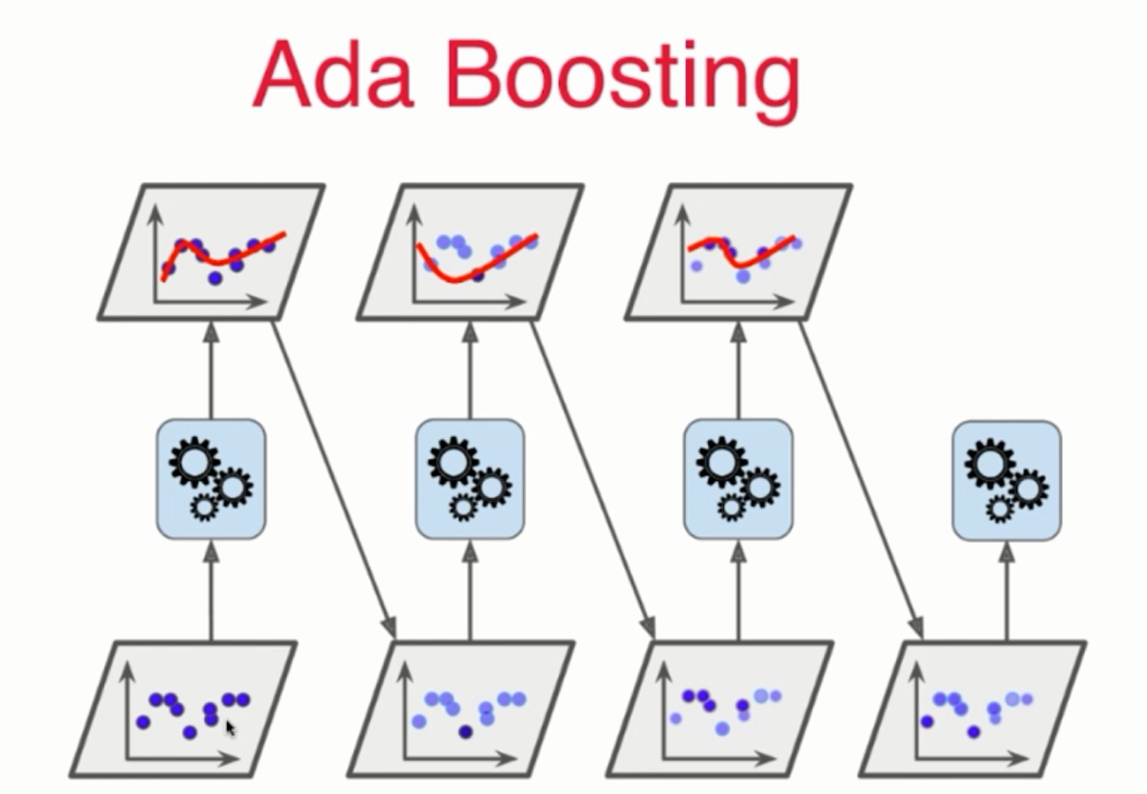
Ada Boosting思路,对每次学习后,无法较好拟合的数据点,在下次拟合过程中,增加这些数据点的权重,依次循环生成子模型
from sklearn.ensemble import AdaBoostClassifierada_clf = AdaBoostClassifier(DecisionTreeClassifier(),n_estimators=500)ada_clf.fit(X_train,y_train)ada_clf.score(X_test,y_test)

Gradient Boosting思路,对于上次拟合错误的数据点,给与下一个模型专门训练,依次循环
#GradientBoostingClassifier本身基于决策树进行,因此不需要设置best_estamitorfrom sklearn.ensemble import GradientBoostingClassifierada_clf = GradientBoostingClassifier(n_estimators=500)ada_clf.fit(X_train,y_train)
转载地址:http://mmbsl.baihongyu.com/
你可能感兴趣的文章
Linux下配置JavaWeb环境(持续更新其他软件)
查看>>
Java之数组array和集合list、set、map
查看>>
Java异常了解
查看>>
管理员修改文件的权限
查看>>
Java注释@interface的用法
查看>>
桥接模式(Bridge)
查看>>
系统架构师具备的能力和构架师自我培养过程
查看>>
发布几个常用Docker基础环境镜像
查看>>
ThinkPad L412 安装Mac 10.7.2 显卡驱动安装成功
查看>>
xcode升级之后,VVDocument失效的解决办法
查看>>
easymock快速入门
查看>>
Ubuntu16.04 安装ftp
查看>>
????常用注意事项
查看>>
【★】KMP算法完整教程
查看>>
自制VTP实验总结
查看>>
[转载]Word直接发布新浪博客(以Word 2013为例)
查看>>
android简单分享----文字加图片
查看>>
01真假
查看>>
常用正则表达式
查看>>
发通知 PendingIntent 中Intent 内容没有更新
查看>>